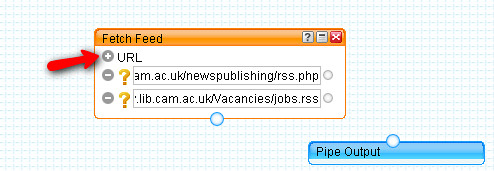
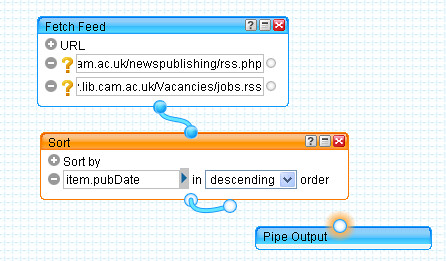
In the post
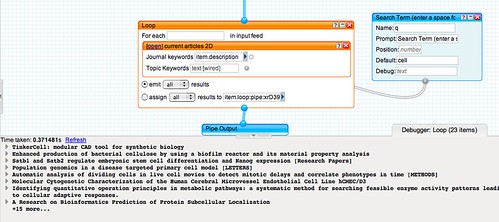
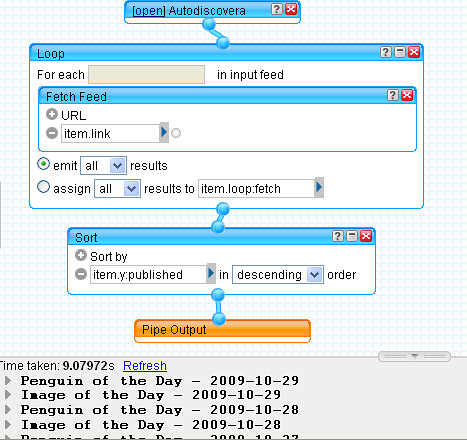
Getting Started With Yahoo Pipes: Merging RSS Feeds, I described how it's possible to merge two or more RSS feeds within a Yahoo pipe in order to produce a single combined feed.
But what happens if there is no feed available from a website or a webpage? Is there any way we can bring that content into the Yahoo Pipes environment, perhaps so that we can combine it with a 'proper' RSS feed? Well it so happens that there
are several other ways of bringing content into a Pipe, other than by subscribing to an RSS feed, and I'll describe one of them here: importing an HTML page directly, and turning a particular section of it into an RSS feed.
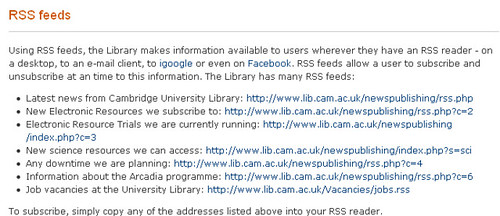
As an example, let's consider the following page on the
talks@cam website:
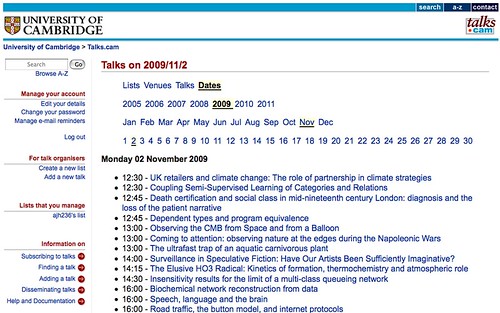
Although many of the list types on the talks@cam website support a wide variety of output formats (including RSS), the daily full fat feed doesn't appear to. The only option is the HTML output (unless someone can tell me how to find a feed? That said, this post
is all about making do with what we've got and consequently generating RSS from an HTML page...)
If we look at the HTML code that generates the page using the
View Source option from the browser
View menu, we can (eventually) see that the page is structured quite neatly.
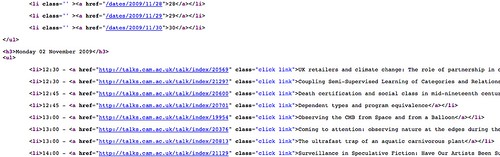
(Just because the page looks neat and tidy in the full browser view doesn't necessarily mean the HTML code is nicely structured!).
In particular, we can see that there is a repeating element at the start of each calendar entry - in particular, the
<li> element - and that each listing item follows a similar pattern, or structure. So for example, if we look at:
<li>12:45 - <a href="http://talks.cam.ac.uk/talk/index/20701" class="click link">Dependent types and program equivalence</a></li>we see it has the structure:
<li>TIME - <a href="EVENT URI" class="click link">EVENT DETAILS</a></li>This is how it appeared on the rendered web page in the browser:

The <li> defines a list element, which is rendered in the browser as a list item starting with a bullet; the <a> tag defines a link, with the defined URI and link text.
Now suppose that we would like an RSS feed where each item in the feed corresponded to a separate event. How might w go about that?
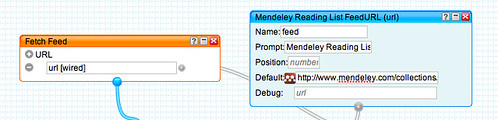
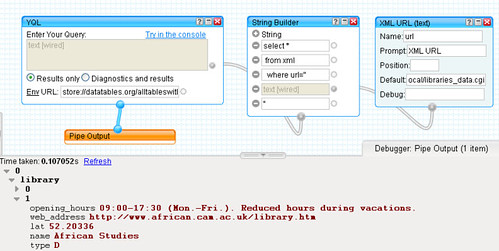
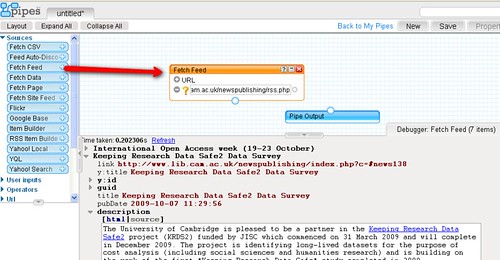
The first step is to bring the HTML page into the pipes environment using the Fetch HTML block from the Pipes' Source menu. The URI
http://talks.cam.ac.uk/dates appears to pull up the events for the current date (though a more exact URI pattern of the form
http://talks.cam.ac.uk/dates/YEAR/MONTH/DAY such as
http://talks.cam.ac.uk/dates/2009/11/3 also pulls up the page for a particular date) so that's the one we'll use:
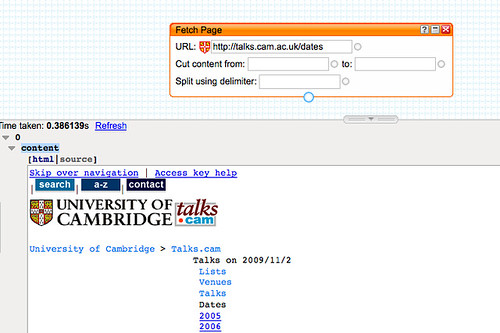
You'll see the pipe has brought the web page into the pipe context. As well as previewing the rendered web page, we can inspect the HTML by clicking on the
source in the Previewer:
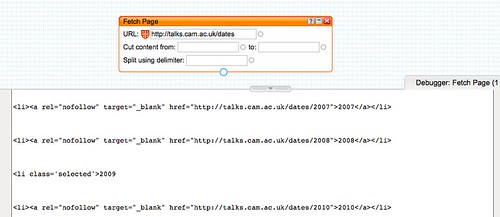
You'll notice that the
Fetch Page block allows us to declare where we want to
Cut content from, and
to and also how we want to
split it. That is, we can specify some HTML code in the page that tells the pipe where the 'useful' part of the page starts (that is, that part of it we want to "scrape" the content from), and where the useful part of the page (as far as we're concerned) ends,
and what piece of repeating HTML we want the pipe to use to separate out the different items contained in the page.
To star with that 'delimiter', we recall each item in the event list starts with <li>, so we shall use that as our delimiter.
But how do we know where the useful HTML starts, and where it ends? We have to find that by trial and error through inspecting the HTML. We need something that appears for the first time in the page close to thee start of the useful content, and something that appears for the first time after that just after the end of the useful content. (If necessary, we might have to grab an excessively large piece of HTML from the page .)
Not that in the current case, whilst it might look like
<h3>Monday 02 November 2009</h3> provides us with a unique place from which to start cutting content, if we look at the listing for a different today's date, there will be a different set of characters there...!
Using the </h3> tag as the start of the useful content, and </ul> as the end, we can tell the pipe to cut out the useful listings:

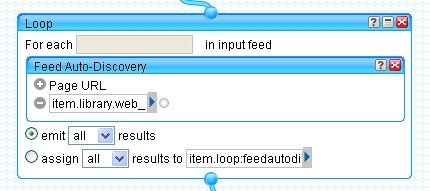
Adding the <li> delimiter gives us a crude set of items, one for each event:
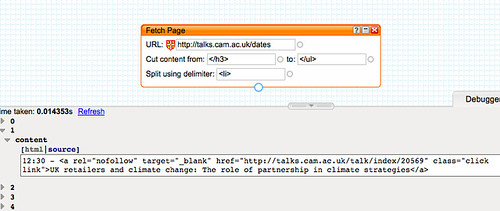
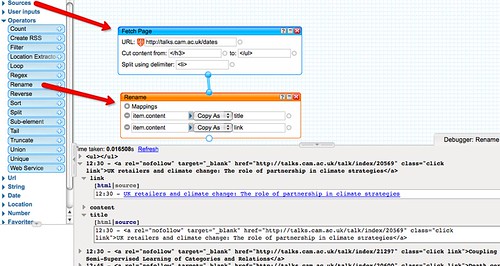
In order to turn these items into 'proper' RSS feed items, we need to define a title, and ideally also a link for the event. We can create, and prepopulate these links using the
Rename block from the
Operators menu:
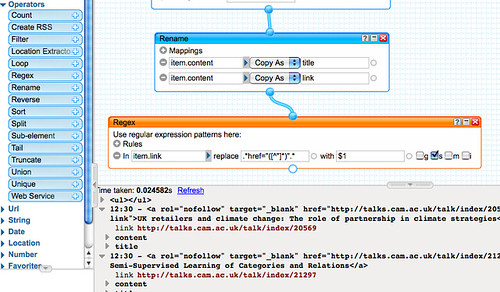
We now need to tidy up those elements with a
Regex (
Regular Expression) block. Regular Expressions are like voodoo magic - they let you manipulate a string of characters in order to transform that string in all sorts of ways. Written correctly, they can be very powerful and look very elegant. I tend use them in a pidgin way, fumbling my way to a solution using simple rules of them and tricks I've use before!
So for example, I know that the pattern
.*href="([^"]*)".* will strip out the URI from a single line of text, that contains a link, and place it in the variable $1.
(The . stands for 'any character'; the * says 'zero or more of the preceding character (or any character for a preceding .); the expression [^"]* says 'a set of characters []* that isn't ^ a "; the () marks out the set of contiguous characters that will be passed to the variable $1;
href=" and the final " are literal string matched characters. The whole string of matched characters are then replaced by the contents of the $1 variable. The
s is ticked so that the pipe will cope with any excess whitespace characters.)
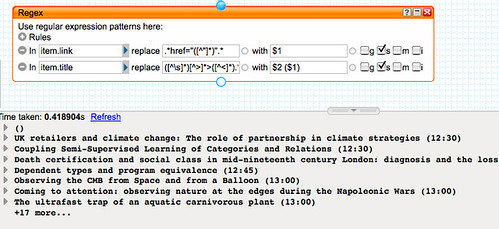
A second regular expression -
([^\s]*)[^>]*>([^<]*).* replaced by
$2 ($1) - this time applied to the
title element, extracts the name of the talk and the time.
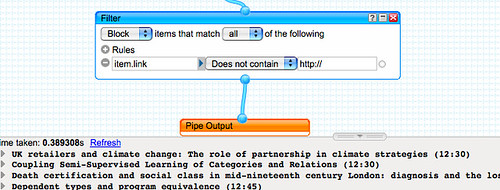
Finally, we tidy up the output of the feed to remove any items that don't also link to an vent record on talks@cam (that is, we remove items where an event link was not extracted by the regular expression.)
And to tidy up the presentation a little more, we click in the title tab to give the pipe an appropriate name:

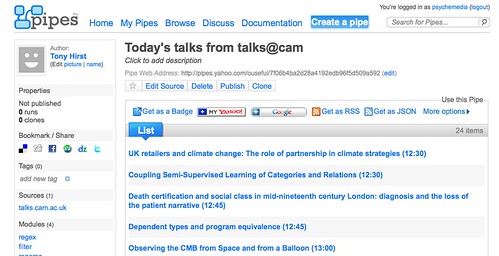
If we now
Run the pipe, we can grab a link to an RSS feed of today's talks@cam:
 In a follow on to this post, I'll show how to bring time into the equation and add a timestamp for each event to each item in the feed.
In a follow on to this post, I'll show how to bring time into the equation and add a timestamp for each event to each item in the feed.