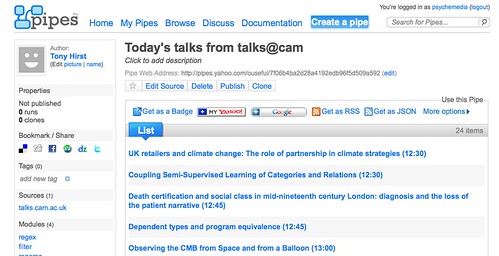
(If you're new to Yahoo Pipes, check out the introductory post "Getting Started With Yahoo Pipes: Merging RSS Feeds", which shows how Pipes work, and leads you through a get you startd activity to create a pipe that merged several RSS feeds to produce a single, aggregate feed.)
In particular, in this demonstration I'll show how it's possible to use a pipe that either you yourself, or someone else entirely, might have already built, within a new pipe of your own.
To set the scene, suppose you have a list... a list of resources... a reading list, for example. In and of itself, this might be a key resource in the delivery of a course, but might it also be more than that? Whenever I see a list of web resources, I ask myself: could this be the basis of a custom search engine that searches over just those resources, or just the websites those resources live on? So where might this thought take us in the context of a reading list?
Over on the Arcadia blog, I showed how Mendeley might be used to support the publication and syndication of reading lists (Reading List Management with Mendeley), using a list built around references to a series of journal articles as an example; this list, in fact: "Synthetic Biology" Collection, by Ricardo Vidal.
One of the nice things about Mendeley public collection is that they expose an RSS feed of the collection, so might we be able to use Yahoo Pipes to:
- extract a set of journal titles from a list, and then
- create a watchlist over the current tables of contents of those listed journals
to keep us up to date with the some of the recent literature in that topic area?
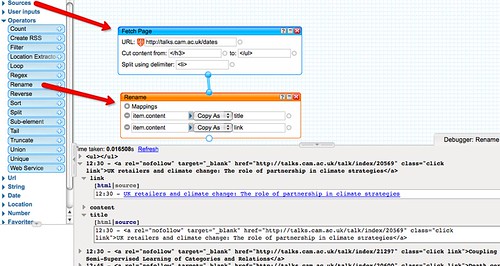
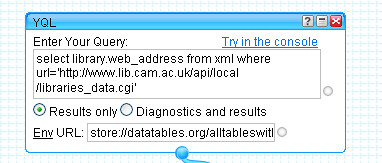
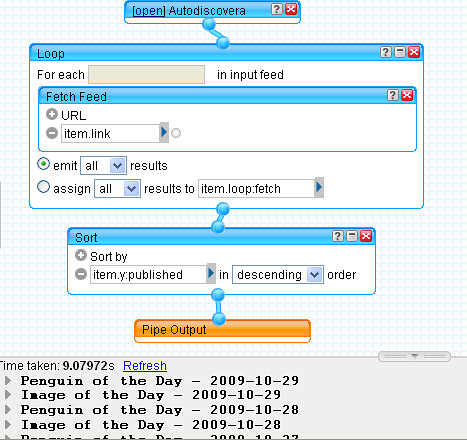
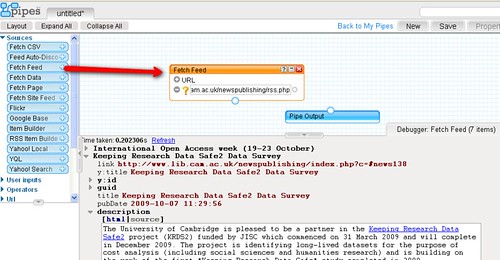
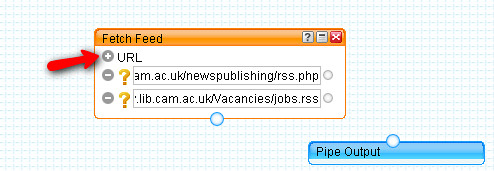
To start with, let's look at how we might grab a list of current contents feeds, filtered by keyword, for the journals listed in the Mendeley Reading list identified above. The first thing to do is import the reading list feed into the pipes environment:
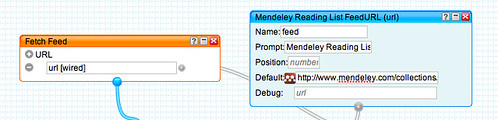
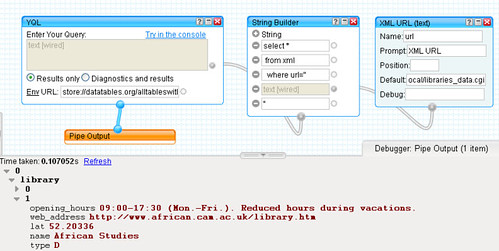
The way this list has been constructed we can find a reference to the journal in the description element:
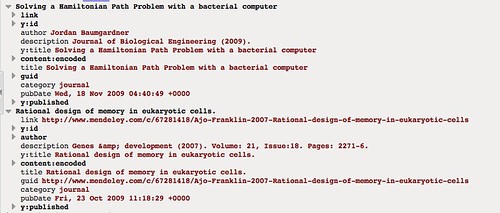
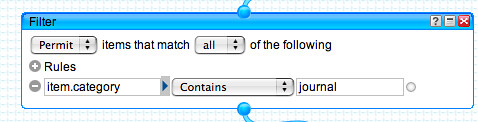
We also note that a "journal" category has been used, which we could filter the items against:
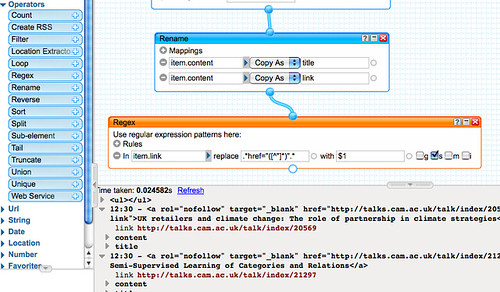
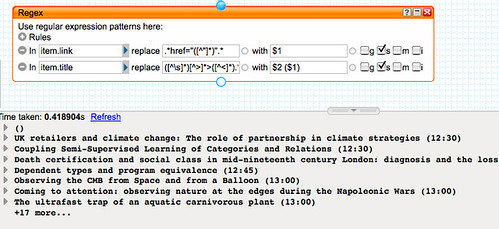
Extracting the journal title from the description requires the use of a heuristic (rule of thumb). Noticing that the description typically contains references of the form Journal title (year), volume, page reference etc., we can use a regular expression to strip out everything after and including the first bracket that opens on to a numeral 1 or 2:

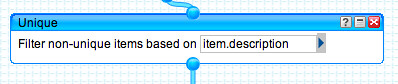
The second step of the regular expression block simply groups the title as a search phrase within quotation marks. Using a Unique block removes duplicate entries in the feed so we don't search for the same journal title more than once.
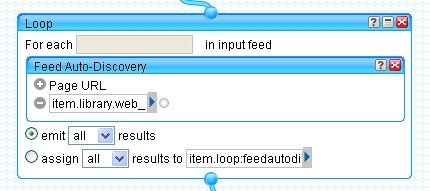
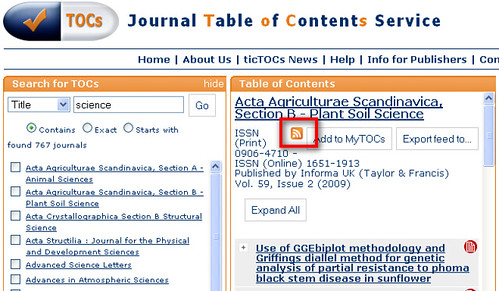
To grab the filter contents feed, we use the Loop block to search Scott Wilson's JOPML service (which provides a search interface over journal titles indexed by the TicTocs current journal contents service) using the 2D Journal Search block I put together after the last mashlib:
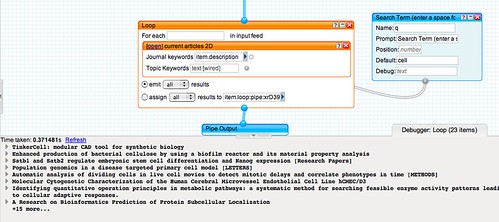
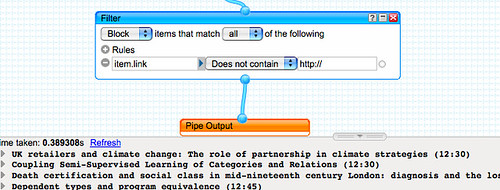
So what do we have now? The ability to pull out a list of unique journal titles (hopefully!) and then use these as publication search terms in a JOPML search for publications indexed by TicTocs; a set of keyword/topic search terms are then applied to the titles of articles in the current issue of the listed journals, in order to provide a watchlist of articles on a particular topic from a list of journals as identified in a reading list. (To display all the content, simply use a space character as a search term.)
by looking at the data returned by the 2D search pipe, we also get a few ideas for further possible refinements:
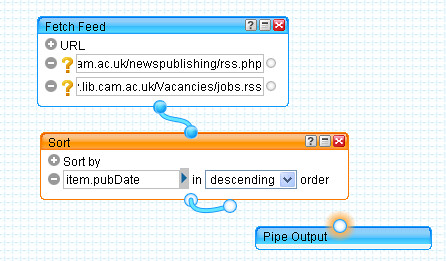
For example, we might sort the results by publication title, or use a regular expression to annotate the title with the name of the journal it came from.
You can find a copy of the pipe here: Mendeley Reading list journal watcher.