What this means is that if you have a list of links to library web pages, you can potentially automatically discover any RSS feeds associated with that library (if they have published autodiscoverable feed links, that is).
Some time ago, I put together a quick app that took a screenscraped list of UK HEI Library homepage URIs from somewhere (you wouldn't believe how hard it is to try to find a list of UK HEI library homepages;-) and tried to autodiscover any RSS feeds associated with them - Autodiscoverable RSS Feeds From HEI Library Websites. When I ran the detector just now, I got about a 36% success rate, which is far better than this time last year...
So anyway, I was wondering: how do the Cambridge University Libraries fare?
Looking through my list of handy cam.ac.uk links, here's one for an XML feed of the associated libraries, with links to their homepage: http://www.lib.cam.ac.uk/api/local/libraries_data.cgi

Notice that the URI for the web page of each library can be found down the XML path: libraries.library.web_address
So let's bring this in to a Yahoo Pipes environment, and try to autodetect any RSS feeds linked to from those pages. As well as importing RSS, Yahoo Pipes can also import JSON and XML feeds using the Fetch Data import block. However, I've noticed that the Fetch Data block sometimes chokes (I'm not quite sure why) so instead I use another Yahoo service - YQL - to act as an intermediary that will fetch the xml, maybe process it a little for me, and then pull the result into the pipe:
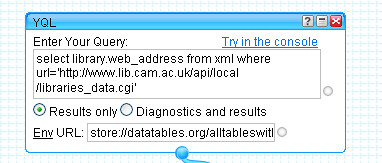
(You can try this query in the YQL Developer console.)
What the query statement does:
select library.web_address from xml where url='http://www.lib.cam.ac.uk/api/local/libraries_data.cgi'
is grab all the library.web_address elements (that point to the homepage for each library) from the XML page at http://www.lib.cam.ac.uk/api/local/libraries_data.cgi and pass them in to the pipe as XML.
NB it's trivial to create a simple 'helper' pipe block that acts like a mimimal Fetch Data block but actually pulls in the XML file via YQL:
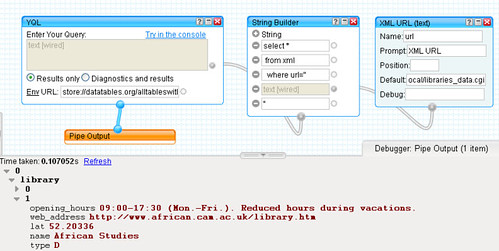
This block could then be included in a pipe in the same way that a Fetch Data block can be...
So what next? Well, now we can use the Feed Autodiscovery block to see if there are any autodiscoverable RSS feeds listed on those web pages.
In order to do this, we need to pop the Feed Autodiscovery inside a Loop block - this allows the pipe to grab any autodiscovered feed URIs and produce a new feed of feed URIs by replacing the original elements that point to the Library homepages. The Emit all results instruction enforces this replacement policy.
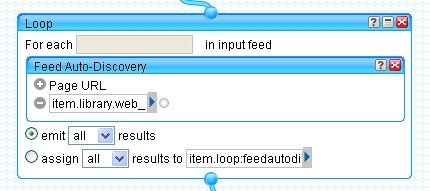
So to recap - we grab a list of webpage URIs fromn the Cambridge Libraries XML feed:

Then we replace those feed items by any and all autodiscovered feed URIs:

(Who'd have thunk it - Penguin of the Day;-).
Note that the pipe also reports on any broken links it finds in the original homepage list:

We can now use this pipe in another pipe that looks at all the autodiscovered feed URIs, pulls the contents of them into a single feed, and then maybe sorts them by date order (as described in Getting Started With Yahoo Pipes: Merging RSS Feeds):
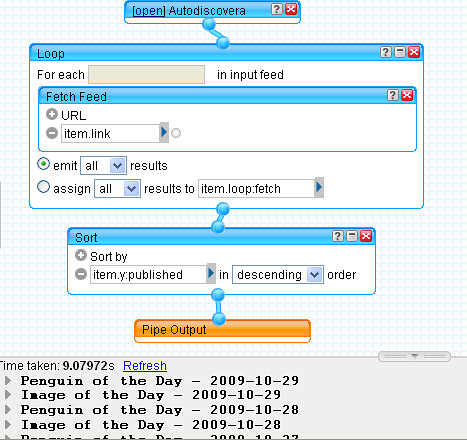
Again, the pipe reports on any feed URLs that appear to be broken:

So there we have it - a pipe that contains the aggregated feed items from the autodiscoverable RSS feeds listed on Cambridge University Library homepages, all powered by a single XML file containing links to the Library homepages.
No comments:
Post a Comment